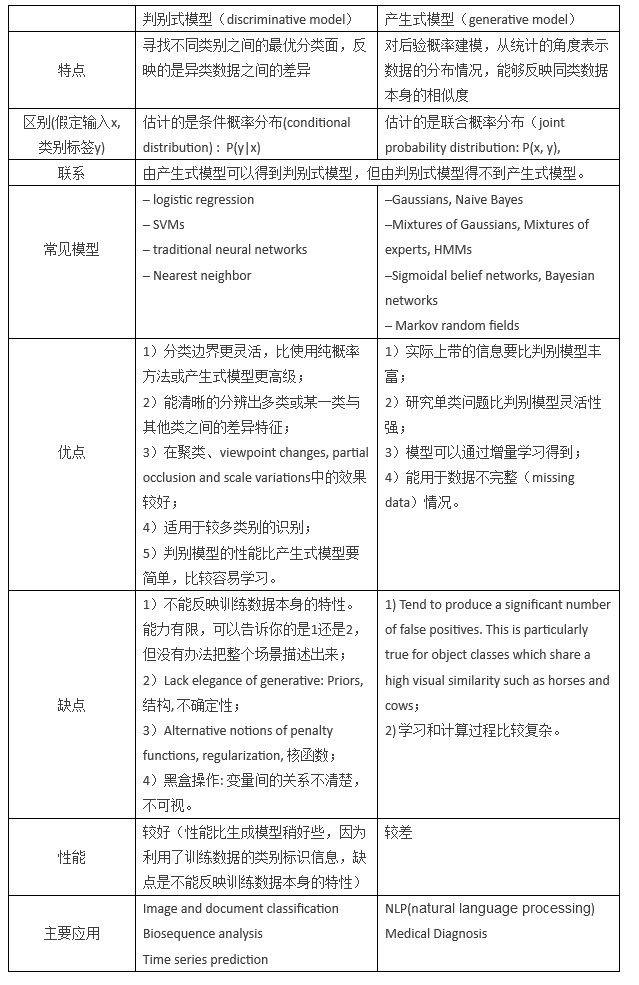
首先,两种模型都属于监督学习中的分类。
生成式模型(Generative Model):
输入特征x,标签为y,求联合概率分布p(x,y);常见的模型有:Gaussians、Naive Bayes、Mixtures of Multinomials、Mixtures of Gaussians、Mixtures of Experts、HMMs、Sigmoidal Belief Networks, Bayesian Networks、Markov Random Fields、Latent Dirichlet Allocation。
优点:
-
生成给出的是联合分布P(x,y),不仅能够由联合分布计算条件分布P(y x)(反之则不行),还可以给出其他信息,比如可以使用P(x)=P(x y)* P(y)来计算边缘分布P(x)。如果一个输入样本的边缘分布P(x)很小的话,那么可以认为学习出的这个模型可能不太适合对这个样本进行分类,分类效果可能会不好,这也是所谓的outlier detection; - 生成模型收敛速度比较快,即当样本数量较多时,生成模型能更快地收敛于真实模型;
- 生成模型能够应付存在隐变量的情况,比如混合高斯模型就是含有隐变量的生成方法。
缺点:
- 天下没有免费午餐,联合分布是能提供更多的信息,但也需要更多的样本和更多计算,尤其是为了更准确估计类别条件分布,需要增加样本的数目,而且类别条件概率的许多信息是我们做分类用不到,因而如果我们只需要做分类任务,就浪费了计算资源;
- 另外,实践中多数情况下判别模型效果更好。
判别式模型(Discriminative Model):
| 输入特征x,标签为y;求条件概率分布p(y | x);常见的模型有:LR、SVM、Traditional Neural Networks、Nearest Neighbor、CRF、Linear Discriminant Analysis、Boosting、Linear Regression。 |
优点:
- 与生成模型缺点对应,首先是节省计算资源,另外,需要的样本数量也少于生成模型;
- 准确率往往较生成模型高;
-
由于直接学习P(y x),而不需要求解类别条件概率,所以允许我们对输入进行抽象(比如降维、构造等),从而能够简化学习问题。
缺点:
- 是没有生成模型的上述优点。
再来一个表格来对比一下两个模型。